<< Home | About Forth | About TurboForth | Download | Language Reference | Resources | Tutorials | YouTube >>
[ This article is important. Some of the secrets of Forth are revealed in here... Sshhhh! ]
For Joshua
Arrays are something that you soon get to grips with in most programming languages. Just about every programming language supports them.
Except Forth.
Yes. It's a bit strange really, but Forth provides no built-in support for handling arrays of... well... anything, really.
So you can't do arrays in Forth, right? Wrong. The reason you don't get arrays "out of the box" in Forth is simply this:
In Forth, you can implement your own arrays, and make them work just like you want them to.
In this article, I'm going to present my own solution, which is tiny and solves the "array problem" in a Forth-like way (i.e. making Forth do as much of the work for us, so that we don't have to).
The cool thing about Forth is that when you write Forth "code" you're just extending the language. Each new word that you write becomes part of the language, and we can use this (and indeed, you're supposed to) to our advantage. We're going to invent a little array handling lexicon (group of words) to give TurboForth support for 16-bit (1 cell) integer arrays.
Lets take a look at the typical syntax that one uses in BASIC and C for handling arrays of integers. Lets use cats as an example. We'll have a four element array that holds the number of lives for four cats: Tom, Dick, Harry, and er, Fred.
Here is how we might do this in BASIC and C:
| BASIC | C |
| DIM CATS(4) | int cats[4]; |
Looks okay to me. How would we do this in Forth? Well, it's Forth, and unlike C and BASIC, we can extend the language any way we see fit. We just have to write the code and it just "becomes" part of the language.
When we declare VALUEs in Forth (a kind of variable that pushes its value to the stack when we reference it) we give it an initial value via the stack, and a name, like this:
4 VALUE CATS
So, 4 goes on the stack, the word VALUE executes, and he (VALUE) knows he has to create a new entry in the dictionary for this new value. Where does he get the name from? Well, it comes immediately after the word VALUE, so VALUE itself reads the input in front of itself and gets the name and creates it. This would work well for us with arrays: It's Forthy and Forth users would be comfortable with it immediately. In Forth, it's "common sense".
How about this to declare an array:
size [] name
So, that's the size of the array (we're only going to talk about integer arrays), then that weird [] thing (which is what is actually going to create the array for us) and then the name of array, so that we can reference it in our code later. So:
9 [] lives
Would declare an integer array of 9 elements, called "lives". That [] symbol is just two square brackets. It's a Forth word (that we're going to create). Remember that in Forth you can call a word anthing you like, as long as it doesn't have a space in its name. So, we'll use [] as a kind of pictogram, since array access in C, Java and Pascal is accomplished with square brackets (BASIC being the odd one, as it uses parenthesis) so [] should be obvious to us that we're dealing with arrays.
Okay, so we have a way to declare an array. Now we need a way to write data into the elements of the array. Again, lets look at existing Forth practice for this:
In Forth, when writing to variables with the word ! we first place the value to store on the stack, then the variable to store it in, then the word ! takes this information off the stack and uses it to perform the write action, like this:
variable score
999 score !
Since anyone that uses Forth would be comfortable with this, it makes sense to use the same idiom if we can. However, we need three items to go on the stack:
Like this:
4 5 lives
So, we want to write the value 4 into the 5th element of the lives array. But, just like ! with variables, we need a word to do the writing for us. Well, it's Forth convention to use the symbol ! to represent writing values to something, since ! has been used to write to variables since at least 1970. So, we really should pick something similar for our lexicon that follows this convention, so that it conveys meaning to the reader.
I elect (because I'm writing this article) the word/symbol [!]
4 5 lives [!]
Here, again we're using the [] nomenclature to indicate that we're dealing with an array, but we have that rather cool ! inside the brackets, which is synonymous with ! which means write. So, the above reads as:
The stack signature for [!] would be:
value element array --
Which simply means that [!] exepcts the value, the element, and the array itself on the stack, and it removes them when it's done.
So, how to read from the Array? Well, when we read variables, we use the word/symbol @ (fetch). @ just needs an address on the stack, and then it uses that address, goes and reads that address and pushes whatever it finds there onto the stack. Again, we should use the same principle, as the concept is already established in Forth and we should avoid completely new paradigms and nomenclatures unless we have no choice; they're just harder to remember later on.
I elect [@] as our word to read from an array. It will need two items on the stack: The element number, and the array itself:
5 lives [@]
So, the above would read the 5th element from the lives array, and place it on the stack. The stack signature is:
element array -- n
So, after [@] executes, it removes the element number and the array reference from the stack, and leaves a value (n) for us - the value that it read from the array.
That's probably enough to get us started writing code. Strap in...
Well, the first word we need to tackle is [] creates an array for us.
There is a very useful word in Forth called CREATE which, er, creates stuff for us. Specifically, it creates words in the dictionary. We're going to go on a little detour here and discuss CREATE for while, because it does a little more than just creating a word in the dictionary for us. The words it creates are smart; they actually inherit some special built in behaviour: They push the address of themselves. Let's look at an example:
create chaos
If you type this directly into the TurboForth command line, it will dutifully obey you, and go ahead and create that word for you. You can now execute that word, straight away, which is a little weird, since the word has no code associated with it. Nevertheless, go ahead and try it:
As you can see, when we executed chaos something was pushed on the stack for us. What is that? Well, words created with CREATE reserve one cell (in TurboForth, a 16-bit (2 byte) word) of 'storage space'. In addition, words created with CREATE inherit some behaviour such that, when they are executed, they push the address of this storage space to the stack (if you are familiar with objects, you can think of words created with CREATE as objects of class CREATE, and they have a single static method, which pushes the address of its storage). In memory, it would look like this (let's assume chaos is stored at memory address B000 hex to keep things simple):
| Link Field | Length Field | Name | Code Field | Parameter Field |
A3B0 |
5 |
c h a o s _ |
63E0 |
0 |
The link field is the link to the previously defined word in the dictionary and is not important to us. The length field just holds the length of the name (plus some other info, again not important to us). Then comes the 5 bytes of the name, plus a padding byte since it's an odd length. Then the Code Field. Now things are getting interesting. This is the address of some code that is executed when you execute chaos (this is where chaos' inherited behaviour comes from). So, when you execute chaos it will actually execute some code at address 63E0 (just chosen for illustration purposes - i've no idea where it goes in reality, and I wrote TurboForth!).
What does that code do? It pushes the address of the parameter field. It's called a parameter field because we can store, well, a parameter in it. Personally I'd have called it a data field, but what do I know?
Lets prove it:
Here, we have created chaos, then we used ! to store 99 into it. Then we read it back.
Let's look at how this works:
Then we read it back:
If you're thinking "Hang on, that's just the same as a Forth variable" then congratulations. You're right. In fact the definition of VARIABLE in Forth is:
: VARIABLE CREATE ;
So, now that we know that know about CREATE, we can use it (and some other tricks) to build our array defining word for us, which we have called [].
We're going to built this up as we go, illustrating concepts as we go. Little steps.
As we determined above, we need to declare an array of a specific size (which is going to be passed in on the stack), so CREATE is only going to get us so far... We still need a way to reserve some storage space. I'll just go ahead and give you the code, and then we'll break it down. You'll probably have some "aha!" moments along the way. Later on, we're going to make it more sophisticated, but first we'll keep things simple. Here's the code for our array creation word, called [] (which I pronounce out loud as (drum roll...) "create array").
: [] ( size tib:"name" -- ) create dup , cells allot ;
Not a lot of code is it, but there's quite a lot going on here, as you're about to see. Hang in there. It's worth learning this stuff.
First, the stack signature:
size tib:"name" --
This indicates that [] needs a size on the stack, and also needs the name of the array in the Terminal Input Buffer (tib). What on earth is the terminal input buffer? It's the buffer that you are typing stuff into on the TurboForth command line. This is just a fancy way of saying that [] requires the name of the array to follow the [] itself, like this:
10 [] years
So, let's go through step-by-step, and see what happens when you type 10 [] years into TurboForth:
| Link Field | Length Field | Name Field | Code Field | Data Field | 20 bytes (10 cells) reserved | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
A0FE |
5 |
y e a r s _ |
63E0 |
10 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | HERE |
As you can see, HERE is now pointing at the address just after the last byte of our array. The next word that we create in the dictionary will start "HERE". That's why it's very important that we include bounds checking. If we didn't, then the word [!] (when we get around to writing it) could possibly destroy other words in the dictionary if we supplied an out-of-range value for the element number.
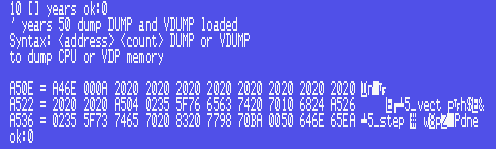
Let's use DUMP to actually look at the array in memory.
: [] ( size tib:"name" -- ) create dup , cells allot ;
10 [] years
' years 50 DUMP
The above line uses the word ' (pronounced tick) to get the address of the word 'years', we then put 50 on the stack, and call DUMP. DUMP takes the address off the stack, and the 50 (which is the number of bytes to display) and shows us the data.
See the 000A there in the second cell? That's the size of the years array, then 20 bytes of reserved space (here they have the value 20 (hex) but they could have any other value (ALLOT does not initialise the allotted space to zero)). After that, you can see the word _vect which is actually a word used by the DUMP utility. Now you can see that without bounds checking (which we haven't done yet) we could potentially write into any area of memory and destroy the dictionary.
Next, we'll add the ability to write to the array...
As discussed above in the Writing To The Array section, our [!] word will need three items on the stack. In order, these are:
Therefore the stack signature is:
value index array --
As we can see, there is nothing on the output side of the stack comment, meaning that [!] will consume its arguments (they'll be removed) which is standard practice. Let's roll up our sleeves and build the definition up:
: [!] ( value index array -- ) swap cells + cell+ ! ;
So, remember when [!] executes, it expects three items on the stack, as shown in the stack comment.
The first thing it does is SWAP the index and array, such that the index is at the top of the stack. When we use [!] we'll be specifying the index in cells (16-bit words), so we execute CELLS which converts it to bytes.
Now we execute + which adds the newly converted number of bytes to the array address. The stack now looks like this:
value array_address
Okay, pretty good. However, we have a problem... We are storing the size of the array itself in the first cell of the array space, so we need to step over it. We need to add 2 to the address to make it point to the data-space immediately after the array size.
Now, we could simply execute 2 + (or, even better, 2+) to add two to the address, and that would be perfectly fine. However, we're going to use the word cell+ which actually does the exact same thing (adds 2 to the value at the top of the stack). So why use cell+ instead of 2+? Simply because cell+, as a synonym of 2+ describes the intention of the code better. It tells the reader that we're moving to the next cell in memory, rather than adding 2 to your Space Invaders score, for example.
Okay, so we now have an address at the top of the stack, and a value underneath it, which is all that the word ! ("store") needs to do its work, so next we execute ! and the value is stored in the correct place in the array. Let's try the whole thing from scratch. Type COLD into TurboForth to reset it, and enter the following code:
36 load
: [] ( size "name" -- ) create dup , cells allot ;
: [!] ( value index array -- ) swap cells + cell+ ! ;
The "36 load" loads the DUMP utility so that we can inspect memory.
Now type the following:
10 [] years
1949 0 years [!]
1970 1 years [!]
1977 2 years [!]
1978 3 years [!]
1980 4 years [!]
1981 5 years [!]
1985 6 years [!]
' years 50 dump
Here we can see the contents of our array. Here's what we've got:
Yes, I do know the year of release of every Dire Straits album, and the in-order track listing of every album. I know what you're thinking.
Okay, so far so good. We can write to the array. Now we need to add some code to read from the array. We'll prove it works then re-visit both [!] and [@] and add bounds checking later.
Here's the definition of [@]:
: [@] ( index array -- value ) cell+ swap cells + @ ;
Here's the break-down:
And we're done.
That wasn't too bad was it? And, crucially, we've just defined our own way of handling arrays, which can be used in any program we write from now on.
The above is all very well, but without bounds checking on our arrays, we run the risk of writing to areas outside of the array, with potentially disastrous results.
Consider this:
5 [] my_array
: test ." Hello Mother" cr ;
$2046 14 my_array [!]
$6174 15 my_array [!]
test
See? We can modify code anywhere in the system. Here, we modified a string, so we got away with it, but we could have written into the executable code of a word and crashed the system easily. These types of bugs can be very difficult to find, because it would look like the bug occurred inside the word that got blasted over, and not in the code that did the blasting!
Adding bounds checking to our word is very simple, and, since the bounds checking will be common to both words, we'll put it in its own word, and then [!] and [@] can both use it.
We'll create a word called [?] which checks the array index against the allowed size, and will either take no action if the index is legal, or abort if it's illegal.
So the stack signature for [?] will be:
index array -- index array
This is a little unusual, as this word does not consume or change its arguments. It's normal convention for words to consume their arguments. However, that would mean that we'd have to use 2DUP to duplicate the index and array in both [!] and [@], and I don't like that. So, I'm going to have [?] do it instead. If [?] detects an out of bounds access, it will abort with an error message and the program will stop running (and the stack will be cleared). If there is no bounds violation, the index and array address will remain on the stack un-changed.
: [?] ( index array -- index array ) over abs over @ > abort" Array index out of bounds" ;
Since both [!] and [@] are going to use this word, it needs to be defined first. Thus, the whole program together becomes:
: [] ( size tib:"name" -- ) create dup , cells allot ;
: [?] ( index array -- index array ) over abs over @ > abort" Array index out of bounds" ;
: [!] ( value index array -- ) [?] swap cells + cell+ ! ;
: [@] ( index array -- value ) [?] cell+ swap cells + @ ;
Before we discuss how the bounds checking works, it's worth taking a moment to reflect on how much code there isn't. The above code compiles to 128 bytes. That's with bounds checking. And not only that, we implemented arrays exactly the way we wanted to, and, we can change it later if there's something we don't like about it.
Okay, lets take a look at how [?] works, as things probably look a little confusing in there:
The first thing to note is that when [?] is called, the index and array (at least) are on top of the stack. In the stack diagrams below I'll use green to indicate stack items that were on the stack before the word executes, and red to indicate stack items that the word itself puts there as it's executing. If the bounds are being checked as part of [!] then we actually have value, index, and array address on the top of the stack, but we're only interested in the top two: the index, and the array address.
We use OVER to move a duplicate of the index "over" the array address, to the top of the stack:
index array index
Then we use ABS to check the index value. If the value is 0 or positive, the index will be un-changed. If the index is negative (for some bizarre reason) then ABS will change the index to a positive value. For example: -3 becomes 3.
Now we use over again move a duplicate of the array address "over" the index, to the top of the stack:
index array index array
Now we execute @ which uses the array address on the top of the stack and reads the size of the array, which, as we learned above, is stored in the parameter address of the array. So our stack looks like this:
index array index size
Next we excute > which compares the index to the size. When > executes it consumes the size and index and leaves a flag on the stack (either TRUE (-1) or FALSE (0).
If the flag left on the stack is true, ABORT will abort the running program, and issue the error message. Otherwise it will take no action (apart from removing the true/false flag on the stack).
Thus at the end of the word, if no index error occurs, then we are just left with the original index and array on the stack, which is used by both [!] and [@].
And there, dear Forthers, is a simple implementation of arrays with bounds checking in 128 bytes. Nothing fancy, nothing flash. Just what's needed.
That's Forth.
Published 7 June 2017
<< Home | About Forth | About TurboForth | Download | Language Reference | Resources | Tutorials | YouTube >>